Appearance
Joining Data, SQL, and an Introduction to RegEx
Resources
Joining Data
SQL
- W3, SQL Basics
- R4DS Chapter 19
- SQLite: Python sqlite3, R dbplyr
RegEx
- R4DS Chapter 14
- P4DA §7.4
- RegEx Cheat Sheet
Use the readings for depth; this page is a hands-on guide to what we’ll use and why.
Overview
This week we focus on three practical skills:
- Joining data: combine related tables into one analysis-ready data frame.
- SQL basics: query and store data in relational databases.
- Regular expressions (RegEx): find and manipulate text via patterns.
Each builds directly on Weeks 1–3 (data frames, plotting, EDA, cleaning).
Joining Data
A join merges two tables by matching key columns. The result depends on the join type:
- Inner join: only matches present in both tables.
- Left join: keep all rows from left; attach matches from right.
- Right join: mirror of left join.
- Full/outer join: keep all rows from both; unmatched become missing.
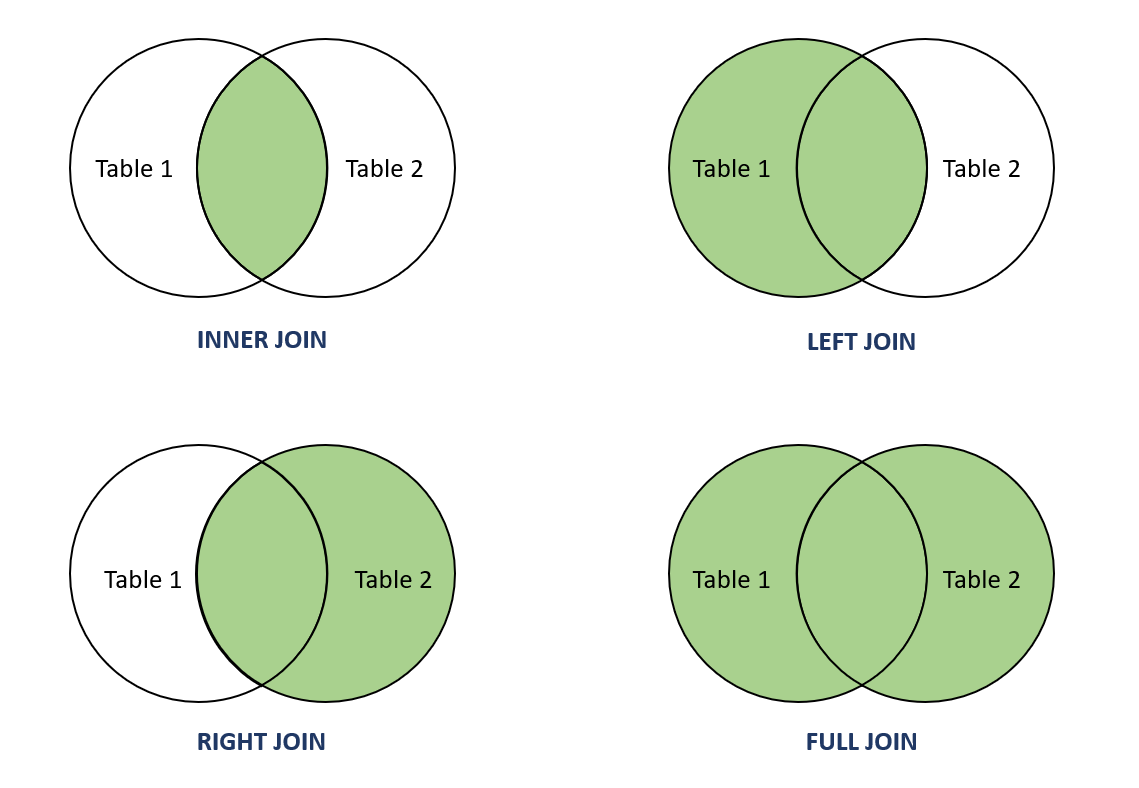
Image credit: alphacodingskills.com
Join two tables at a time. For more tables, join iteratively in a clear order.
Minimal patterns (Python & R)
Python
import pandas as pd
# Example keys must be clean and unique (or you’ll multiply rows)
left = pd.DataFrame({"id":[1,2,3], "x":[10,20,30]})
right = pd.DataFrame({"id":[2,3,4], "y":[200,300,400]})
inner = left.merge(right, on="id", how="inner")
leftj = left.merge(right, on="id", how="left")
rightj = left.merge(right, on="id", how="right")
outer = left.merge(right, on="id", how="outer")R
library(dplyr)
left <- tibble::tibble(id = c(1,2,3), x = c(10,20,30))
right <- tibble::tibble(id = c(2,3,4), y = c(200,300,400))
inner <- left %>% inner_join(right, by = "id")
leftj <- left %>% left_join(right, by = "id")
rightj <- left %>% right_join(right, by = "id")
outer <- left %>% full_join(right, by = "id")Sanity checks: compare row counts before/after; check for duplicated keys; inspect a few rows of the join result.
SQL (Structured Query Language)
SQL is how we query and manage relational databases. Data lives in tables related by keys; you select columns, filter rows, and join tables by keys.
Relational layout
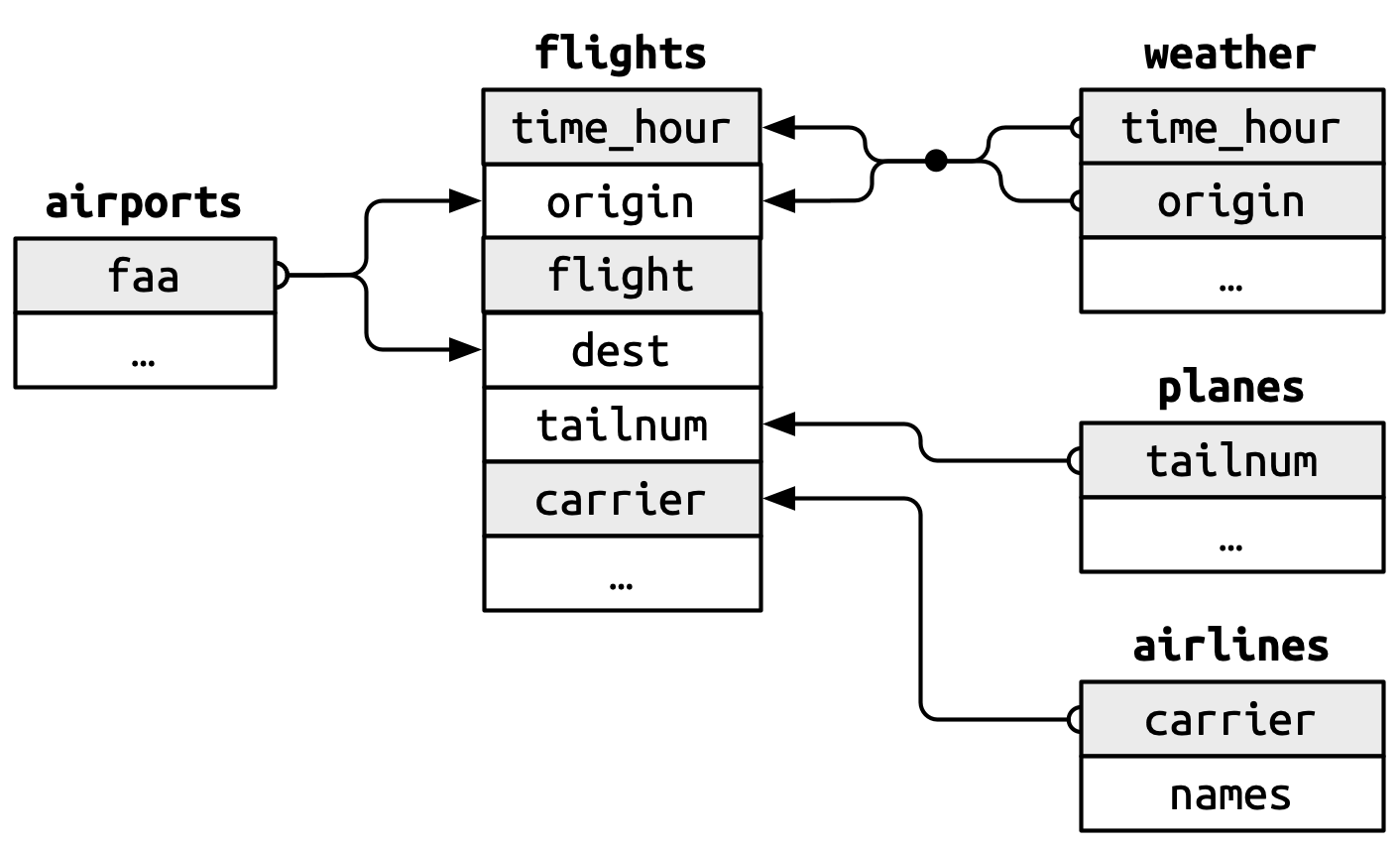
Image borrowed from r4ds.hadley.nz
Basic querying
Select columns and rows from a table:
SQL
SELECT carrier, dest, tailnum
FROM flights;Get all columns with *:
SQL
SELECT *
FROM flights;Filter rows with WHERE and logical operators:
SQL
SELECT carrier, dest, tailnum
FROM flights
WHERE dest = 'Sweden' AND carrier <> 'XX';Join tables with matching keys:
SQL
SELECT f.carrier, f.dest, f.tailnum, a.name
FROM flights AS f
LEFT JOIN airlines AS a
ON f.carrier = a.carrier;Creating and storing data
Define tables and constraints to keep data clean:
SQL
CREATE TABLE Persons (
Name VARCHAR(255) NOT NULL,
Age INT,
ID_number VARCHAR(255) PRIMARY KEY
);
CREATE TABLE Computers (
Computer_id INT PRIMARY KEY,
Model VARCHAR(255),
Brand VARCHAR(255),
Owner VARCHAR(255),
FOREIGN KEY (Owner) REFERENCES Persons(ID_number)
);Alter an existing table:
SQL
ALTER TABLE Persons
ADD Occupation VARCHAR(255);Insert rows:
SQL
INSERT INTO Persons (Name, ID_number)
VALUES ('Taariq', '19000101-XXXX');Constraints like
PRIMARY KEY,NOT NULL,UNIQUE,FOREIGN KEYprevent bad data at the source.
Using SQLite from Python/R
Python
import sqlite3
import pandas as pd
con = sqlite3.connect("example.db")
cur = con.cursor()
cur.execute(\"\"\"
CREATE TABLE IF NOT EXISTS persons (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER
);
\"\"\")
cur.execute("INSERT INTO persons (name, age) VALUES (?, ?)", ("Ada", 36))
con.commit()
df = pd.read_sql_query("SELECT * FROM persons", con)
con.close()R
library(DBI)
library(RSQLite)
library(dplyr)
con <- dbConnect(RSQLite::SQLite(), "example.db")
dbExecute(con, "
CREATE TABLE IF NOT EXISTS persons (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
age INTEGER
);
")
dbExecute(con, "INSERT INTO persons (name, age) VALUES ('Ada', 36)")
df <- dbGetQuery(con, "SELECT * FROM persons")
dbDisconnect(con)RegEx (Regular Expressions)
RegEx matches text patterns. It’s ideal for validation (emails, phone numbers), extraction (IDs, tags), and cleaning (whitespace, formatting).
Quick tour of building blocks
- Literals: exact characters (e.g.,
abc). - Metacharacters:
.any char;^start;$end;|OR;()groups. - Character classes:
[aeiou],[^0-9]. - Quantifiers:
*0+,+1+,?0/1,{n},{n,},{n,m}. - Predefined classes:
\ddigit,\wword,\swhitespace (capitals negate). - Anchors:
\bword boundary,\Bnon-boundary. - Escapes:
\.for a literal dot.
Example: extract emails from text
regex
\b[\w._%+-]+@[\w.-]+\.[A-Za-z]{2,4}\bBreakdown: \b word boundary; username class [...] +; @; domain class; literal dot \.; TLD {2,4}; boundary.
Example: match only example.com emails
regex
\b[A-Za-z0-9._%+-]+@example\.com\bRunning RegEx in Python/R
Python
import re
text = "Contact support@example.com or info@company.com."
pattern = r"\b[\w._%+-]+@[\w.-]+\.[A-Za-z]{2,4}\b"
emails = re.findall(pattern, text)
# ['support@example.com', 'info@company.com']R
library(stringr)
text <- "Contact support@example.com or info@company.com."
pattern <- "\\b[\\w._%+-]+@[\\w.-]+\\.[A-Za-z]{2,4}\\b"
emails <- str_extract_all(text, pattern)[[1]]
# c("support@example.com", "info@company.com")Exercises
Try these in a notebook; keep your reasoning next to the code.
1) Email validation
john.doe@example.com
jane.smith@gmail.com
alice.jones123@yahoo.com
invalid.email@domain- Extract valid emails (must contain
@and a TLD like.com,.org, …). - Report invalids separately.
2) Phone numbers
Phone numbers:
123-456-7890, (555) 987-6543, 9876543210, 555-1234
Invalid: 12-345-6789, 555-98765, abcdefgh- Extract US-like formats above as valid; flag the rest as invalid.
3) HTML tags and attributes
<p class="intro">This is a <strong>sample</strong> paragraph.</p>
<p>No class here.</p>
<div id="container" class="main">
<h1>Title</h1>
<p>Content</p>
</div>- Extract start tags (
<p ...>,<strong>,<div ...>). - For
<div>, also extractid="..."andclass="..."attribute pairs.
You can run RegEx from Python (
re) or R (stringr). The cheat sheet above is handy while you practice.